|
I am a staff research scientist at Meta Reality Labs, specializing in generative AI for 3D content creation. My work focuses on building and deploying state-of-the-art pipelines for text-to-3D asset and world generation, avatar creation. I lead the development of several 3D GenAI projects powering Meta’s next-generation creator tools and XR platforms. I am passionate about driving technical innovation in generative AI, and shaping the direction of world modeling. I did my Ph.D. at Purdue University, where I was advised by Jan Allebach. I received my Bachelor's degree from Tsinghua University. Email / CV / Bio / Google Scholar / Twitter / Github / LinkedIn |

|
|
|

|

|

|

|
|
|


|
Tzofi Klinghoffer, Siddharth Somasundaram, Xiaoyu Xiang, Yuchen Fan, Christian Richardt, Akshat Dave, Ramesh Raskar, Rakesh Ranjan ACM SIGGRAPH Asia (SIGGRAPH Asia), 2025 [Paper] [Suppl] [Code] [Project Page] [Dataset] A single-shot method for occlusion-aware 3D reconstruction from lidar by decomposing two-bounce light. Meta Synthetic Environments Lidar Dataset is released. |
|
|
Dilin Wang, Hyunyoung Jung, Tom Monnier, Kihyuk Sohn, Chuhang Zou, Xiaoyu Xiang, Yu-Ying Yeh, Di Liu, Zixuan Huang, Thu Nguyen-Phuoc, Yuchen Fan, Sergiu Oprea, Ziyan Wang, Roman Shapovalov, Nikolaos Sarafianos, Thibault Groueix, Antoine Toisoul, Prithviraj Dhar, Xiao Chu, Minghao Chen, Geon Yeong Park, Mahima Gupta, Yassir Azziz, Rakesh Ranjan, Andrea Vedaldi arXiv, 2025 [Paper] [Blog] A system that enables the automatic creation of large-scale, interactive 3D worlds directly from text prompts, producing traversable, fully textured environments for game engines. |

|
Nikolaos Sarafianos, Tuur Stuyck, Xiaoyu Xiang, Yilei Li, Jovan Popovic, Rakesh Ranjan arXiv, 2024 [Paper] [Suppl] [Code] [Project Page] [Video] [Data] Garment3DGen stylizes the geometry and textures of real and fantastical garments that we can fit on top of parametric bodies and simulate. |


|
Tzofi Klinghoffer, Xiaoyu Xiang*, Siddharth Somasundaram*, Yuchen Fan, Christian Richardt, Ramesh Raskar, Rakesh Ranjan IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024 (Oral, Best Paper Award Finalist) [Paper] [Code] [Video] [Dataset] A method to recover scene geometry from a single view using two-bounce signals captured by a single-photon lidar. |


|
Yunyang Xiong, Bala Varadarajan*, Lemeng Wu*, Xiaoyu Xiang*, Fanyi Xiao, Chenchen Zhu, Xiaoliang Dai, Dilin Wang, Fei Sun, Forrest Iandola, Raghuraman Krishnamoorthi, Vikas Chandra IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024 (Highlight) [Paper] [Code] [Video] [HuggingFace] A light-weight SAM model that exhibits decent performance with largely reduced complexity. |

|
Shuai Yuan, Lei Luo, Zhuo Hui, Can Pu, Xiaoyu Xiang, Rakesh Ranjan, Denis Demandolx, IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024 [Paper] [Appendix] [Code] [Poster] [Video] [BibTex] An unsupervised flow network that leverages object information from the latest foundation model Segment Anything Model (SAM). |

|
Ziyu Wan, Despoina Paschalidou, Ian Huang, Hongyu Liu, Bokui Shen, Xiaoyu Xiang, Jing Liao Leonidas Guibas IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024 [PDF] [Project Page] [Code] [Video] A new approach for generating high-quality, photoreaslisitc and diverse 3D objects conditioned on a single image and a text prompt. |

|
Hai Wang, Xiaoyu Xiang, Yuchen Fan, Jing-Hao Xue IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2024 [PDF] [Project Page] [Code] Synthesize seamless 360-degree panoramas with given text prompts. |


|
Bala Varadarajan, Bilge Soran, Xiaoyu Xiang, Forrest Iandola, Yunyang Xiong, Lemeng Wu, Chenchen Zhu, Naveen Suda, Raghuraman Krishnamoorthi, Vikas Chandra arXiv, 2023 [Paper] [Code] SqueezeSAM is 62.5x faster and 31.6x smaller than its predecessor, making it a viable solution for mobile applications. |

|
Ziyu Wan, Christian Richardt, Aljaž Božič, Chao Li, Vijay Rengarajan, Seonghyeon Nam, Xiaoyu Xiang, Tuotuo Li, Bo Zhu, Rakesh Ranjan, Jing Liao IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023 [PDF] [WebGL Viewer] [Project Page] [Video] Represent scenes as neural radiance features encoded on a two-layer duplex mesh, overcoming inaccuracies in 3D surface reconstruction. |


|
Yawei Li, Yuchen Fan, Xiaoyu Xiang, Denis Demandolx, Rakesh Ranjan, Radu Timofte, Luc Van Gool IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023 [PDF] [Code] Providing a mechanism to efficiently and explicitly model image hierarchies in the global, regional, and local range for image restoration. |
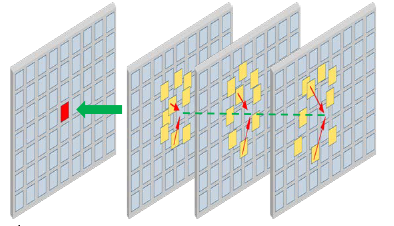
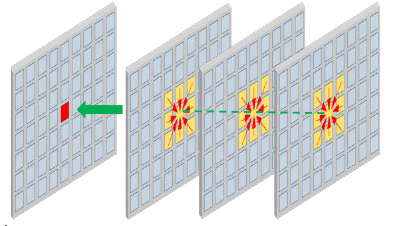
|
Hai Wang, Xiaoyu Xiang, Yapeng Tian, Wenming Yang, Qingmin Liao IEEE Transactions on Neural Networks and Learning Systems (TNNLS), 2023 [PDF] [Code] A deformable attention network that adaptively captures and aggregates spatial and temporal contexts in dynamic video to enhance reconstruction. |
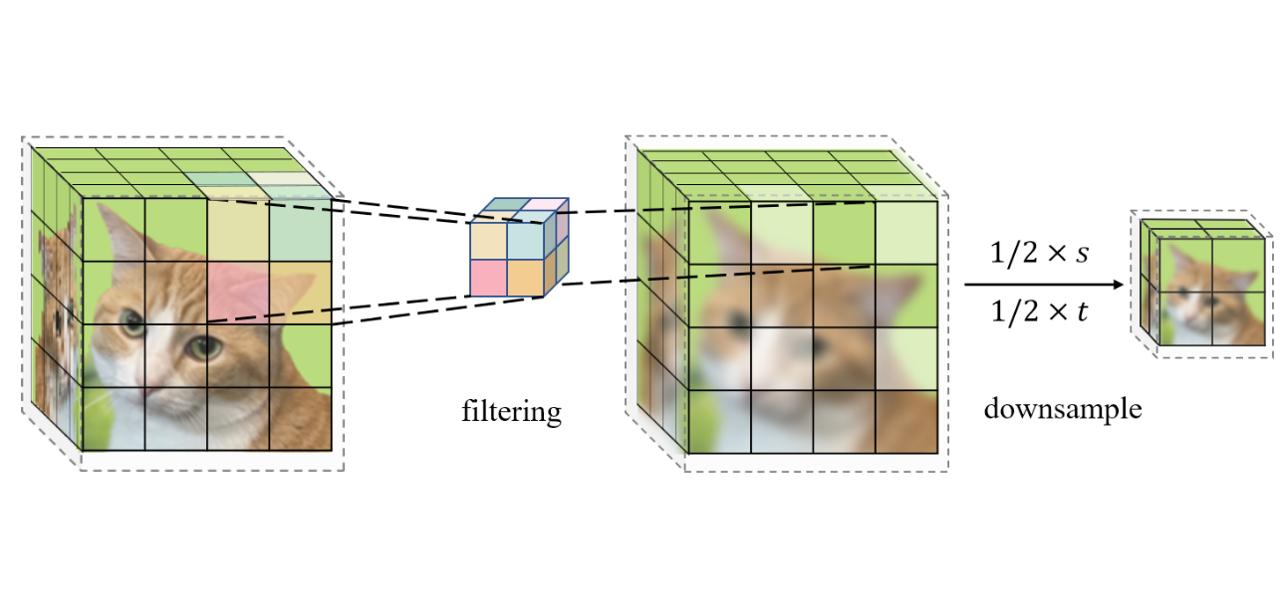
|
Xiaoyu Xiang, Yapeng Tian, Vijay Rengarajan, Lucas Young, Bo Zhu, Rakesh Ranjan European Conference on Computer Vision (ECCV), 2022 [Paper] [Poster] [Video] A method to learn spatio-temporal downsampling for effective video upscaling. |


|
Xiaoyu Xiang, Ding Liu, Xiao Yang, Yiheng Zhu, Xiaohui Shen, Jan P. Allebach IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2022 [Paper] [Code] [Anime2Sketch] [Video] An adversarial open domain adaptation framework for sketch-to-photo synthesis. |

|
Xiaoyu Xiang*, Yapeng Tian*, Yulun Zhang, Yun Fu, Jan P. Allebach, Chenliang Xu IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020 [Paper] [Journal] [Code] [Demo] [Teaser Video] A unified one-stage framework for space-time video super-resolution to directly synthesize an HR slow-motion video from an LR and LFR video. |
|
Organizer: Computer Vision for Mixed Reality Workshop, CVPR 2023, 2024 Program Chair: Electronic Imaging Symposium, 2025-2026 Conference Reviewer: ICLR 2021-2022, CVPR 2021-2024, ICCV 2021-2023, ECCV 2022-2024, NeurIPS 2021-2023, ICML 2022, SIGGRAPH 2024-2025, SIGGRAPH-Asia 2024, WACV 2022-2025 Journal Reviewer: T-PAMI, TNNLS, TMM, NCAA, IEEE Access, Journal of Automatica Sinica, Neurocomputing, Journal of Electronic Imaging |
|
2021.08~ present Research Scientist in Meta Reality Labs 2020.08~2021.03 Research Intern in Facebook Reality Labs 2020.06~2020.08 Research Intern in ByteDance 2018.05~2020.05 Research Student in HP Labs 2017.08~2020.05 Graduate Research Assistant in ECE, Purdue University 2015.07~2017.05 Research Engineer in Optical Fiber Research Center, CAEP 2014.07~2014.09 Summer Research Student in DESY 2012.05~2015.07 Undergraduate Research Assistant in Tsinghua University |